PDF文字提取功能调研【上页】
POC目标:对PDF文件实现文本提取
问题场景:PDF存储文本分两种情况,一种是直接文本,一种是图片内文本。
第一种场景,PDF直接文本提取;
该场景下直接利用API(PdfBox 2.0.13)可实现提取,可识别段落。
代码段:
private static void pdfContent(PDDocument pdf) throws Exception{
PDFTextStripper stripper = new PDFTextStripper();
for(int i =0; i < pdf.getNumberOfPages(); i++){
stripper.setStartPage(i+1);
stripper.setEndPage(i+1);
String pageText = stripper.getText(pdf);
System.out.println("Page " + (i+1) + ": " + pageText);
}
}
运行结果:
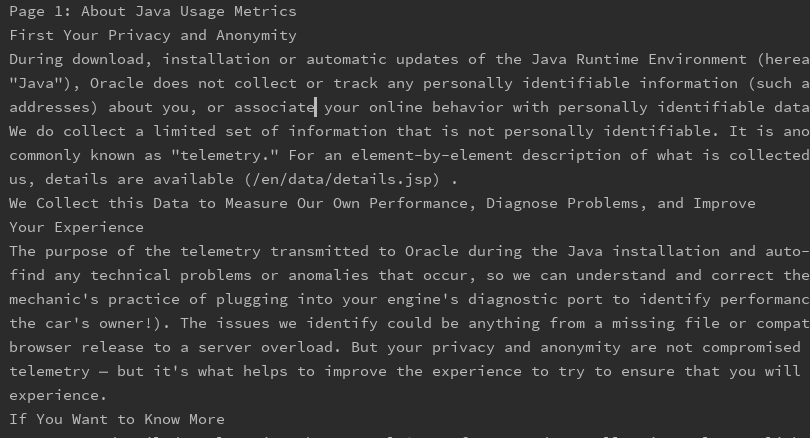
第二种场景,PDF内容为图片,需要提取图片内文字;
该场景下没有直接可用信息,因此需要借助OCR技术进行光学识别获得文字,当前选择的是Google开源的Tesseract-OCR项目,项目本身无需做额外的软件安装,仅必须将外部依赖的jar手动导入项目(当前仅引入了opencv-4.1.0.jar)。
OCR代码段:
public static void printImageText(String filePath){
BytePointer outText;
TessBaseAPI api = new TessBaseAPI();
// Initialize tesseract-ocr with English, without specifying tessdata path
if (api.Init(null, "chi_sim") != 0) {
System.err.println("Could not initialize tesseract.");
System.exit(1);
}
// Open input image with leptonica library
PIX image = pixRead(filePath);
api.SetImage(image);
// Get OCR result
outText = api.GetUTF8Text();
System.out.println("OCR output:\\n" + outText.getString());
// Destroy used object and release memory
api.End();
outText.deallocate();
pixDestroy(image);
}
部分文件是整页为扫描内容,该部分可以直接提取图片进行OCR识别;
代码段(提取并存储PDF中的单页图片):
private static List<String> pdfResource(PDDocument pdf) throws Exception{
List<String> paths = new ArrayList<String>();
String docName = pdf.getDocumentId() + "";
String filePath = "D:\\\TestDoc\\\PDF\\\IMG\\\";
for(int i =0; i < pdf.getNumberOfPages(); i++){
PDPage page = pdf.getPage(i);
PDResources resources = page.getResources();
int count = 1;
for(COSName cn : resources.getXObjectNames()){
if(resources.isImageXObject(cn)){
PDImageXObject Ipdmage = (PDImageXObject) resources.getXObject(cn);
BufferedImage image = Ipdmage.getImage();
String imageName = filePath + docName + "-" + i + "-" + count + ".png";
FileOutputStream out = new FileOutputStream(imageName);
try {
ImageIO.write(image, "png", out);
paths.add(imageName);
count++;
} catch (IOException e) {
} finally {
try {
out.close();
} catch (IOException e) {
}
}
}
}
}
而此场景下出现了文件格式的分歧,同属于图片文件下,部分文件出现了多组件,即对整页有分片,直接获取页面中的图片会导致内容缺失无法识别。
针对此现象,需要先将整页转换为图片,再进行识别。
PDF单页转换代码(返回文件地址):
private static List<String> pdfToImage(PDDocument doc,String filePath) throws Exception{
PDFRenderer renderer = new PDFRenderer(doc);
List<String> imgList = new ArrayList<>();
for (int page = 0; page < doc.getNumberOfPages(); page++){
BufferedImage img = renderer.renderImage(page,0.5f);
String imageName = filePath + doc.getDocumentId() + "-" + page + ".png";
try(FileOutputStream out = new FileOutputStream(imageName)){
ImageIO.write(img, "png", out);
}
imgList.add(imageName);
}
doc.close();
return imgList;
}
在第二种场景中,ocr识别的文字还存在一定问题,比如有空格间隙(可处理),段落错分(本属一段被分开),单引号自动变为双引号,图片中样式干扰,如分割线,图标,页头格式等与内容无关项。
OCR识别效果如下:


从目前得到的结果来看,Tesseract在对中文识别上效果存在不理想的地方,尤其是在标题页或格式复杂页面,常规页面表现效果还能接受(在做了空格段落处理后)。
另外,在该场景的分片情况下,需要先转换后解析,当前设置转换图片比例是0.5,可以降低图片分辨率,提高识别速度。但识别率是依赖于图片分辨率以及图片原始清晰度的,若pdf原内容就存在模糊、倾斜、脏点等情况,会严重影响识别率。
在PDF转换为图片的过程中,转换速度取决于清晰度设置,当前有两种设置方式——DPI和Scale,DPI是固定清晰度的,公式为N*72,N为参数,可让图片统一在固定范围大小,但有可能导致部分内容丰富的图片失真,Scale是基于元素内容的转换,大小不固定,但元素完整度较高。
在100k左右的大小下,解析速度大约为2s,在大于300k的情况下,速度严重放缓,大于1M的可以接近1min,介于此,需要ocr的文件统一转换为图片后再进行识别,能平均文件解析时长,使程序行为更加可控。